
RAGOps – Enabling Production RAG

Let’s keep this precise and visual as possible!
Problem Architecture:
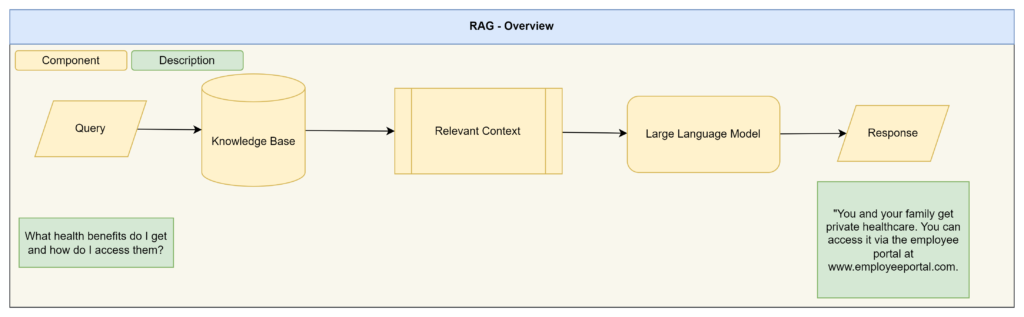
Below is a typical ChatGPT experience, great for general knowledge, but useless on your own data and context;
With Retrieval Augmentation Generation we add in additional steps to essentially replace the general knowledge of a LLM with contextual knowledge:
Pipeline Architecture:
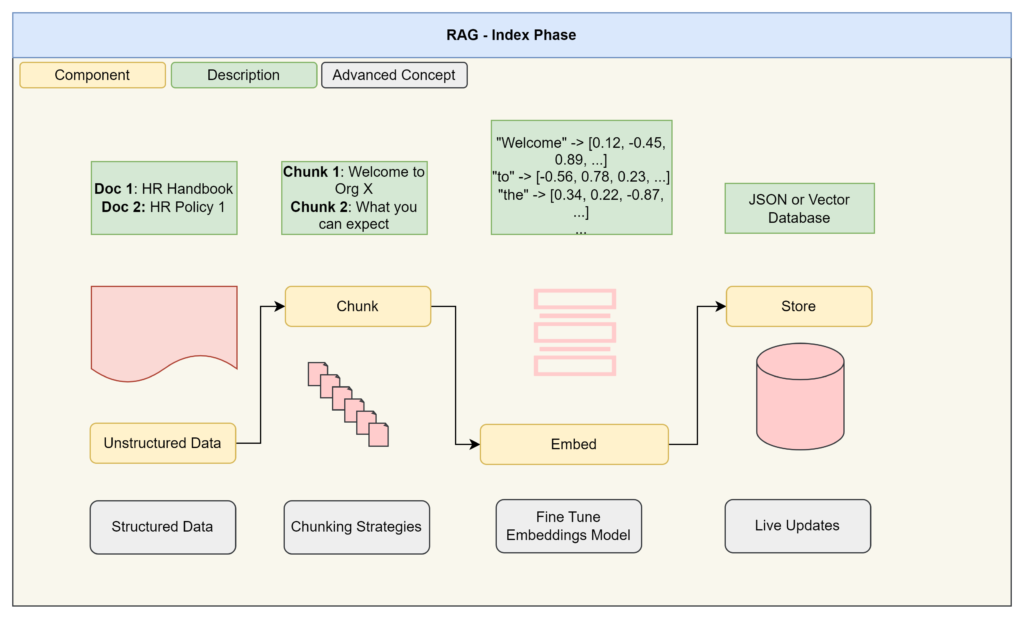
RAG is split into two parts: Index Phase, where we transform our data into a machine readable format which maintains semantic relationships via embeddings:
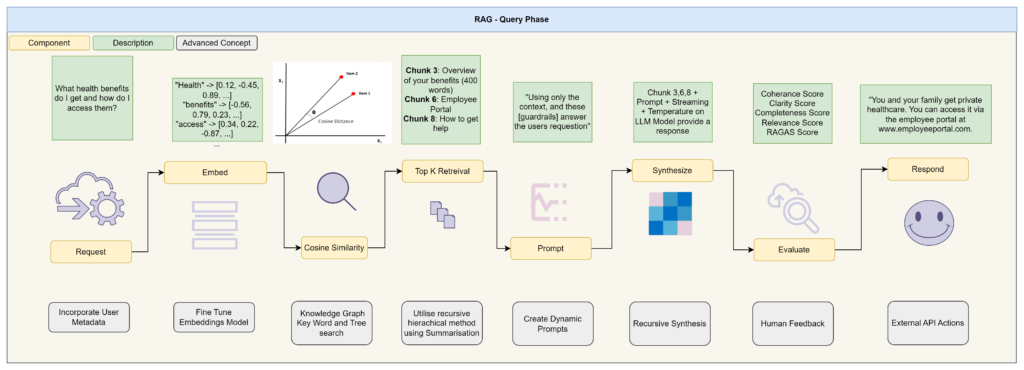
The second phase is the query phase where we transform a question asked via an end user into a contextual response based on our data only:
Simple’s right?
Not so fast! How do you;
– Repeat this process
– Continuously improve this process
– Cater for advance RAG scenarios, like large data sources, like hierarchical data (it is not flat!) and complex relationships
There isn’t a silver bullet answer to this approach, but the emerging practice of RagOps is here to ellievate these constraints.
https://harrisonkirby.net/