RagOps Intro
RagOps stands for “Retrieval-Augmented Generation for Language Models Operations”. It’s a workflow designed to enhance the capabilities of general-purpose language models (LLMs), like GPT-4 or BERT, by incorporating external knowledge sources. This process ensures the generated responses are factually accurate and up-to-date.
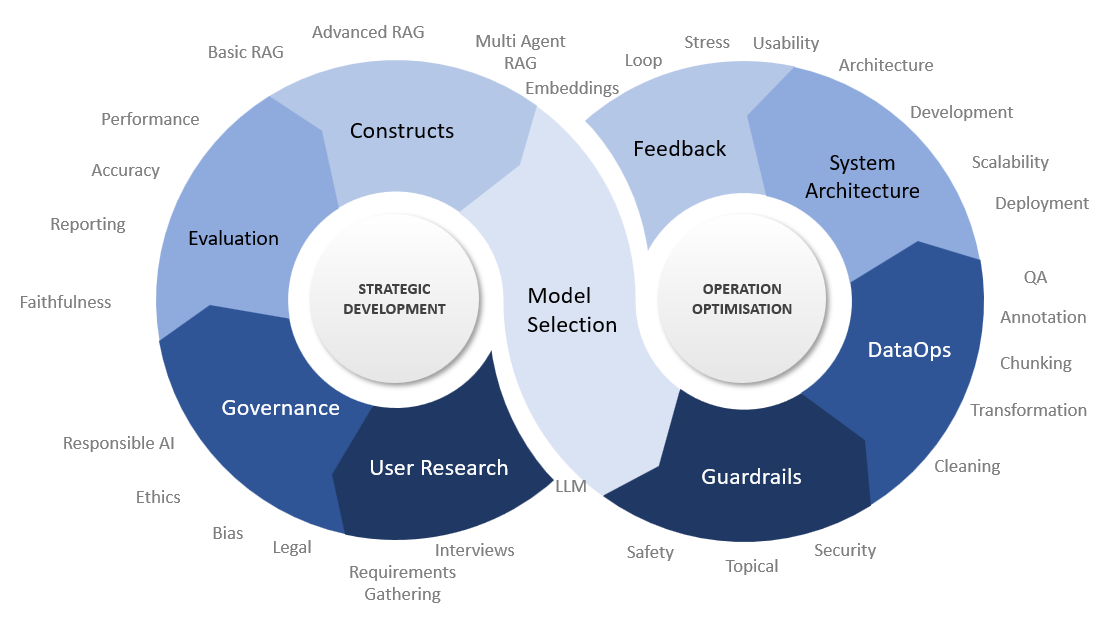
The Infinity Loop Concept
In the dynamic world of Language Learning Models (LLMs), the RagOps system introduces the ‘Infinity Loop’ concept, an emblematic representation of a continual and iterative process designed to enhance the performance and capabilities of LLMs. This innovative approach is not just a linear progression through stages but an endless loop, symbolizing the ongoing nature of learning, adaptation, and improvement. Each phase in the infinity loop is meticulously crafted to address specific aspects of the RagOps system, from understanding user needs to ensuring robust governance, selecting optimal models, preparing data, constructing RAG modules, implementing guardrails, and integrating infrastructure, all leading towards comprehensive evaluation and feedback. This loop embodies the perpetual motion of advancements in AI, ensuring that the RagOps system remains at the forefront of technology, delivering accuracy, relevance, and user-centric solutions.
Phase | Purpose |
User Research | To understand the actual needs and expectations of the end-users, ensuring the system is user-centric. |
Governance | To establish ethical, legal, and operational guidelines for the system, ensuring responsible and compliant usage. |
Evaluation | To assess the system’s performance in accuracy, relevance, and reliability, guiding continuous improvement. |
Constructs | To determine and refine the suitable RAG constructs based on user requirements and evaluation findings. |
Model Selection | To choose the appropriate AI models that will drive the system’s accuracy, speed, and relevance. |
Guardrails | To establish mechanisms ensuring the system operates within the parameters of safety, security, and topical relevance. |
DataOps | To collect, clean, and structure data for training and operating the system effectively. |
System Architecture | To plan both the hardware/software resources and their integration to support efficient system operations. |
Feedback | To conduct comprehensive testing and gather user feedback, linking directly to the evaluation phase for system refinement. |
Each phase of the Infinity Loop is designed to feed into the next, creating a seamless and continuous cycle of improvement. This concept not only ensures that the RagOps system remains cutting-edge but also adaptable and responsive to the evolving landscape of AI and user needs.
Phase Description
Interaction
This phase ensures the system is built to meet the actual needs of its end users. Here’s how you can approach this phase
Step 1: Identify Your User Base
- Demographic Analysis: Understand who the users are in terms of their roles, demographics, and technical expertise.
- User Personas: Create user personas to represent the different types of users who will interact with the system.
Step 2: Conduct User Research
- Surveys and Interviews: Collect data through surveys, interviews, and focus groups to gather insights into the users’ needs and expectations.
- Observational Studies: Observe potential users in their natural environment to understand how they might interact with the system.
Step 3: Gather Requirements
- Functional Requirements: Define what the system should do from the users’ perspective. This includes tasks the system must perform, desired features, and user interaction flows.
- Non-functional Requirements: These are the criteria related to security, performance, scalability, reliability, etc.
Step 4: Analyze Research Data
- Synthesize Findings: Compile the data from user research to identify common pain points, needs, and feature requests.
- Prioritize Requirements: Based on the research findings, prioritize the requirements by their importance to the users and feasibility of implementation.
Step 5: Develop User Stories
- Scenarios: Create detailed user stories that describe how users will interact with the system to perform their tasks.
- Acceptance Criteria: For each user story, define clear acceptance criteria that specify the conditions that the system must meet to satisfy the user requirements.
Step 6: Validate Requirements
- Stakeholder Review: Present the user stories and requirements to stakeholders for validation and ensure they align with business objectives.
- User Feedback: Where possible, get feedback from potential users on the user stories and requirements to ensure they accurately reflect user needs.
Step 7: Create a Requirements Document
- Documentation: Document the user research findings and the finalized list of user stories and requirements.
- Version Control: Implement a version control system to track changes to the requirements document over time.
Step 8: Establish a Feedback Loop
- Continuous Feedback: Establish mechanisms for ongoing user feedback to refine requirements as new information is obtained or as user needs evolve.
Step 9: Plan for Change Management
- Adaptability: Prepare for potential changes in requirements by setting up a flexible system design and agile development practices.
Step 10: Finalize the Requirements Specification
- Sign-off: Obtain sign-off on the requirements document from all key stakeholders to finalize the specification.
By completing this User Research and Requirements Gathering phase with thoroughness and care, you establish a strong foundation for the rest of the RagOps development cycle. This phase ensures that the system is user-centered, addressing real needs, and equipped for effective adoption and satisfaction.
Governance
Creating a governance framework for a RagOps system is essential to ensure it operates ethically, economically, and without bias. This activity involves establishing policies and procedures that guide the development and use of the system, focusing on areas like bias, ethics, and economics. Here’s a structured approach to this governance activity:
Step 1: Establish a Governance Committee
- Composition: Form a committee with diverse expertise, including ethicists, legal experts, data scientists, and end-users.
- Role: This committee will oversee the development and operation of the RagOps system, ensuring adherence to ethical standards and governance policies.
Step 2: Define Ethical Guidelines
- Fairness: Create guidelines to ensure the system treats all users fairly and does not discriminate based on race, gender, age, or other factors.
- Transparency: Develop policies for transparency in how the system processes data and makes decisions.
- Accountability: Establish clear lines of responsibility for decisions made by or with the assistance of the RagOps system.
Step 3: Address Bias
- Data Audits: Regularly audit datasets for biases and take corrective measures to mitigate them.
- Model Testing: Test models for biased outcomes and retrain them as necessary to reduce bias.
- Feedback Mechanisms: Implement mechanisms for users to report perceived biases in the system’s responses.
Step 4: Economic Considerations
- Cost-Benefit Analysis: Regularly perform cost-benefit analyses to ensure the system is economically viable and efficient.
- Resource Allocation: Plan for equitable and efficient allocation of computational and human resources.
Step 5: Legal Compliance
- Regulatory Adherence: Ensure the system complies with all relevant laws and regulations, including data privacy laws and industry-specific guidelines.
- Contractual Obligations: Review and fulfill any contractual obligations related to the system’s use and data handling.
Step 6: Implement Privacy Protections
- Data Privacy: Adhere to strict data privacy standards to protect user information.
- Consent Mechanisms: Develop and implement clear consent mechanisms for users whose data is being collected or processed.
Step 7: Establish Monitoring and Reporting Systems
- Continuous Monitoring: Set up systems for continuous monitoring of the system’s performance, focusing on ethical adherence, bias mitigation, and economic efficiency.
- Reporting Protocols: Create protocols for regular reporting to stakeholders about the system’s governance aspects.
Step 8: Develop Training and Awareness Programs
- Stakeholder Education: Educate stakeholders about the ethical, economic, and bias-related aspects of the system.
- Training Programs: Implement training programs for team members to understand and uphold governance policies.
Step 9: Review and Update Governance Policies
- Regular Reviews: Conduct regular reviews of governance policies to ensure they remain relevant and effective.
- Policy Updates: Update policies as necessary in response to new challenges, technological advancements, or changes in regulatory landscapes.
Step 10: Public Engagement and Feedback
- Engagement Programs: Engage with the public and other stakeholders to gather feedback and perspectives on the system’s governance.
- Feedback Integration: Integrate this feedback into the governance framework to ensure it remains aligned with societal values and expectations.
By following these steps, you can establish a robust governance framework for your RagOps system that addresses key concerns like bias, ethics, and economics. This framework ensures that the system is developed and operated responsibly, transparently, and in a manner that aligns with societal values and legal requirements.
Evaluation
Evaluation is critical ascertain the performance of the RagOps pipeline in terms of accuracy, relevance, and reliability. The purpose of this stage is to tackle “Automation Bias (where one assumes a system works on the basis that it is automated)” and instead provide detailed insight and measurement through the pipeline. This stage is designed to ensure that the generated answers meet the expected standards of quality and are in alignment with the user’s context and the domain’s specificity. This is in line with practices like Evaluation Driven Development which mandate the use of evaluation as the primary conduit.
Expected Inputs
- User Feedback: Direct input from user interactions, noting the perceived quality and relevance of the answers.
- Ground Truth Data: A dataset of pre-validated responses that can be used to compare against the system’s outputs.
- System Outputs: The responses generated by the RagOps pipeline at every stage, ready for assessment.
- Performance Metrics: Predefined criteria that the evaluation will be based upon, including faithfulness, context recall, precision, and relevancy.
Evaluation Process
- Metric Definition: Determine specific metrics like answer relevancy, context recall, precision, and semantic similarity. Define thresholds for each metric that classify performance as acceptable or needing improvement
- Data Collection: Gather outputs from the system alongside corresponding user queries and the context in which they were generated.
- Metric Calculation: Apply quantitative measures to assess the performance of the system, such as semantic similarity algorithms for answer similarity and correctness.
- Comparative Analysis: Compare the system’s outputs to ground truth data to evaluate faithfulness and correctness.
- User Experience Assessment: Perform end-to-end evaluation to understand the user experience holistically, including the efficiency and intuitiveness of the system.
- Dashboard and Alert Configuration: Set up dashboards to visualize evaluation results and configure alerts for when performance metrics fall below acceptable thresholds.
Expected Outputs
- Performance Reports: Detailed reports outlining the system’s performance on each metric.
- Quality Insights: Deep insights into the areas where the system excels and where it requires improvement.
- Alerts and Notifications: Automated alerts for immediate attention where the system’s performance deviates from the set standards.
- Actionable Feedback: Constructive feedback that can be looped back into the system for continuous improvement (evaluation-driven development).
By carefully defining and understanding what to evaluate and how to go about the evaluation, we can ensure that the Evaluation stage serves as a backbone for continuous improvement in RagOps, ultimately leading to a more refined, user-centric product.
RAG Constructs
We now need to factor in our governance, evaluation and user requirements to design, build and refine the appropriate RAG constructs. The options are;
Basic RAG
- Purpose: To provide a foundational RAG setup that handles straightforward question-answering tasks by retrieving information and generating responses based on a single-step process
- Characteristics: This construct is characterized by its simplicity and is best suited for less complex domains where the questions have direct answers that are easy to retrieve.
- Building Process: Implement the core RAG architecture without additional layers of complexity, focusing on efficient retrieval and basic generation capabilities.
Advanced RAG
Purpose
To address complex and nuanced queries that require advanced understanding and synthesis of information from various sources and formats.
Characteristics
- Decoupling of Retrieval and Response: Advanced RAG will separate the processes of information retrieval and response generation, allowing for more flexible and nuanced answers.
- Document and Sentence Summaries: It will utilize summarization techniques to condense large documents and sentences into concise representations, maintaining the context and relevance.
- Metadata: Using tags associated to documents to provide granular and filterable retrieval capability
- Multimodal Capabilities: This construct will handle not only textual data but also other formats such as images and videos, enabling it to understand and generate multimodal responses.
- Cloaking: This component will transform PII type information into non PII information pre LLM whilst maintaining semantic relationships, for example all names become “John Doe”
Building Process
- Decoupled Retrieval and Generation: Implement mechanisms that allow the retrieval of information chunks to be independent of the response generation chunks, enabling a more dynamic response formulation.
- Summarization Techniques: Integrate NLP models capable of generating document and sentence summaries to assist in condensing information into useful snippets.
- Multimodal Data Handling: Develop or integrate models that can process and understand non-textual information, such as Convolutional Neural Networks (CNNs) for image recognition and Transformers for video processing.
- Advanced Embedding Models: Utilize sophisticated embedding models that can capture the subtleties of complex queries, possibly incorporating contextual embeddings like those from BERT or GPT-3.
- Query Transformation Enhancements: Enhance the query transformation process to handle complex sentence structures and domain-specific jargon, possibly using advanced parsing and semantic analysis techniques.
- Fine-Tuning for Contextual Nuance: Fine-tune models on domain-specific data to ensure that nuances and context are accurately captured and reflected in the responses.
- Cloaking Mechanisms: Incorporating SDKs and transformations pre LLM to effectively encode and decode PII information whilst maintaining semantic relationships for cosine similarity lookups.
Evaluation for Advanced RAG Enhanced
- Response Quality: Evaluate the relevance and accuracy of the responses, particularly their faithfulness to the source material and contextual appropriateness.
- Summarization Efficacy: Assess the quality of document and sentence summaries for accuracy and completeness.
- Multimodal Integration: Test the system’s ability to effectively incorporate and respond to multimodal data inputs.
- Complex Query Handling: Evaluate how well the system handles complex and nuanced queries, including those with jargon and sophisticated sentence structures.
- Performance Metrics: Monitor traditional metrics such as speed and resource utilization, as well as advanced metrics like context recall, precision, and relevancy.
Multi-Agent RAG
Purpose
To handle complex scenarios where integrating diverse information sources and perspectives is crucial for generating comprehensive and accurate responses.
Characteristics
- Collaborative Agents: Incorporates multiple RAG instances, each specialized in different domains or data types, to provide a holistic view of information.
- Inter-Agent Communication: Facilitates seamless communication and data exchange among different RAG agents.
- Adaptive Response Generation: Capable of synthesizing information from various agents to create unified and contextually rich responses.
Building Process
- Specialization of Agents: Develop specialized RAG agents, each fine-tuned for specific domains or types of data (e.g., one for scientific data, another for current news).
- Communication Framework: Establish a robust inter-agent communication protocol to allow agents to share insights and data efficiently.
- Consensus Mechanism: Implement a mechanism for resolving conflicts or discrepancies between different agents’ responses.
- Contextual Synthesis: Develop an overarching layer that synthesizes the inputs from various agents into a cohesive response.
Structured RAG
Purpose
To efficiently handle queries involving structured data, offering precise and contextually relevant responses based on structured databases or documents.
Characteristics
- Structured Data Proficiency: Optimized for parsing and understanding structured data formats like SQL databases, XML files, etc.
- Query Execution Capability: Can perform complex operations like executing SQL queries within its retrieval and generation processes.
- Data Integration: Seamlessly integrates structured data sources with unstructured data for comprehensive understanding.
Building Process
- Data Parsing Modules: Implement modules capable of parsing various structured data formats and extracting relevant information.
- Query Execution Engine: Develop a query execution engine that can interact with structured data sources, like executing SQL queries.
- Data Source Integration: Integrate the ability to combine insights from structured data with unstructured data sources for a more rounded response generation.
Pydantic RAG
Purpose
To ensure robust and reliable data handling within the RAG system, emphasizing strict data validation, parsing, and management.
Characteristics
- Data Validation Focus: Uses Pydantic or similar libraries for rigorous validation of data, ensuring it meets predefined schemas.
- Error Handling and Robustness: Designed to be fault-tolerant, with comprehensive error handling and data integrity checks.
- Structured Data Communication: Facilitates structured and reliable communication between different components of the system.
Building Process
- Schema Definition: Define data schemas for all types of data the system will handle, using Pydantic or similar frameworks.
- Validation Mechanisms: Implement validation mechanisms that check data against the defined schemas at every entry and exit point of the system.
- Error Handling Protocols: Develop robust error handling protocols that manage and log validation errors without disrupting the system’s functionality.
In each of these constructs, the Evaluation stage should be customized to assess their unique capabilities and ensure they meet the specific requirements identified. For example, Multi-Agent RAG’s evaluation would focus on the efficiency of inter-agent communication and the quality of integrated responses, while Structured RAG would be evaluated on its ability to accurately process and utilize structured data. Pydantic RAG’s evaluations would concentrate on the system’s adherence to data validation protocols and overall data integrity.
For each of these constructs, the Evaluation stage would need to be tailored accordingly:
- For Basic RAG, evaluation might focus on response accuracy and retrieval speed.
- Advanced RAG evaluation would additionally consider the system’s ability to handle complex sentences and domain-specific jargon.
- Multi-Agent RAG requires evaluation of the system’s coordination and the integration of multiple perspectives into a single coherent response.
- Structured RAG would be evaluated on its ability to correctly interpret and manipulate structured data to provide accurate responses.
- Pydantic RAG evaluations would emphasize the system’s adherence to data schemas and robustness against invalid inputs.
Choosing and building the right construct depends on the specific needs identified during the Evaluation stage, ensuring that the chosen RAG configuration is best suited to meet those needs and is capable of evolving through subsequent iterations of development and evaluation.
Model Selection
Selecting the right models for a RagOps system is critical, as it directly influences the system’s performance, especially in terms of accuracy, speed, and relevance of the generated responses. Here’s a structured approach for the Model Selection Activity:
- Define Model Requirements: Determine the specific needs of your RagOps system, including language, domain specificity, performance expectations, and computational constraints.
- Evaluate Pre-Trained Models: Review available pre-trained LLMs and embeddings models that could be suitable for your system. Consider models like BERT, GPT, RoBERTa, or domain-specific versions if available.
- Benchmarking: Set up benchmarking tasks to evaluate pre-trained models on relevant metrics like accuracy, speed, and resource utilization. Include domain-specific benchmarks to test the models’ performance on tasks similar to those they will encounter in production.
- Fine-Tuning vs. From Scratch: Decide whether to fine-tune existing models or train new models from scratch based on the benchmarking results and the uniqueness of the domain.
- Data Availability: Ensure that there is enough quality data for fine-tuning or training new models. The data should be representative of the use case and diverse enough to train robust models.
- Computational Resources: Assess the computational resources required for fine-tuning or training. This includes considering the availability and cost of GPUs or TPUs if high-performance computing is necessary.
- Model Scalability: Consider how the models will scale as the amount of data increases and as the number of queries grows.
- Ethical and Legal Considerations: Evaluate the models for biases and ethical implications, ensuring they comply with legal standards, particularly in sensitive domains.
- Pilot Testing: Select a few top-performing models from the benchmarking phase and pilot them in a controlled environment. Monitor the models’ performance in real-world scenarios and gather feedback.
- Iterative Evaluation: Use the evaluation framework established earlier to assess model performance in the pilot tests. Apply metrics like faithfulness, context precision, and relevancy to judge the models.
- Integration Readiness: Ensure the chosen models can be integrated smoothly into the existing RagOps architecture with the necessary APIs and data formats.
- Cost-Benefit Analysis: Perform a cost-benefit analysis considering both the initial setup and the long-term operational costs of the models.
- Documentation and Version Control: Document the selection process, model configurations, and versions. Maintain a version control system for model updates and rollbacks if necessary.
- Final Selection: Based on the pilot testing and iterative evaluations, select the model(s) that best meet the system’s requirements.
- Continuous Monitoring and Updating: Plan for ongoing monitoring of the selected models and regular updates based on new data, user feedback, and evolving requirements.
By following this activity, you will have a robust selection process that ensures the chosen LLM and embeddings models are well-suited for the specific needs of your RagOps system, leading to a more effective and reliable deployment.
Guardrails
To devise effective guardrails for a RagOps system, we need to establish protocols and mechanisms that ensure the system operates within the desired parameters of topical relevance, safety, and security. These guardrails are not just preventative measures but also form part of the ongoing evaluation process, providing continuous monitoring and feedback.
Topical Guardrails
Definition
- Topical Guardrails: Ensure that the responses generated by the system are within the scope of the intended domain and are relevant to the user’s query.
Implementation
- Keyword and Phrase Lists: Develop and maintain comprehensive lists of domain-specific keywords and phrases that the system should recognize and prioritize.
- Topic Detection Algorithms: Employ machine learning algorithms to determine the topic of both the query and the response, ensuring alignment.
- Scope Limiters: Set parameters that restrict the system’s retrieval process to domain-specific databases and information sources.
Monitoring in Evaluation
- Topical Accuracy Metrics: Monitor the system’s ability to maintain topical relevance in its responses.
- Query-Response Matching: Regularly evaluate the match between the user’s query topics and the topics of the generated responses.
Safety Guardrails
Definition
- Safety Guardrails: Prevent the generation of harmful, offensive, or inappropriate content in the system’s responses.
Implementation
- Content Filters: Create filters based on a blacklist of harmful or sensitive terms and concepts that the system is programmed to avoid.
- Sentiment Analysis: Utilize sentiment analysis to detect and mitigate negative content in responses.
- User Feedback Loop: Incorporate user feedback mechanisms to identify and correct safety-related issues.
Monitoring in Evaluation
- Content Safety Scores: Evaluate the system’s output for safety by analyzing the presence of flagged content and sentiment.
- Incident Reports: Track and review any incidents where unsafe content was generated to refine safety guardrails continuously.
Security Guardrails
Definition
Security Guardrails: Protect the integrity of the system and the confidentiality of the data it processes from unauthorized access or breaches.
Implementation
- Data Access Controls: Establish strict access controls and authentication protocols to ensure that only authorized personnel can access sensitive data and system configurations.
- Encryption: Apply robust encryption standards to protect data at rest and in transit within the system.
- Audit Trails: Maintain comprehensive audit trails for all system interactions to enable traceability and post-incident analysis.
Monitoring in Evaluation
- Security Compliance Checks: Regularly verify that the system adheres to security policies and standards.
- Breach Detection Mechanisms: Implement automated systems to detect and alert on potential security breaches.
- Regular Security Audits: Conduct periodic security audits to evaluate the effectiveness of the security guardrails and to identify any potential vulnerabilities.
By defining these guardrails and incorporating them into the continuous evaluation cycle, the RagOps system can maintain high standards of topical relevance, safety, and security. The evaluation stage will include metrics and processes to monitor these aspects rigorously, ensuring that any deviations are identified and addressed promptly.
DataOps
In the realm of RagOps, the concept of DataOps stands as a cornerstone, ensuring the system’s effectiveness and optimization. DataOps, short for Data Operations, is pivotal in maintaining the robustness, accuracy, and high quality of the data inputted into the system. It embodies a methodology focused on streamlining the data management process, integrating best practices from the fields of data science, engineering, and software development. By adopting DataOps, RagOps ensures that the data lifecycle – from collection and cleaning to processing and analysis – is managed efficiently, reducing errors and increasing agility. This approach not only enhances the reliability of the system but also ensures that the insights and outputs derived are based on the most relevant and accurate data available, a crucial factor in the success of any AI-driven system.
Step 1: Data Collection
- Gather Data: Compile data from various sources relevant to your domain. This could include datasets, documents, websites, and proprietary information.
- Data Diversity: Ensure that the collected data represents the variety of topics, styles, and formats that the RagOps system will encounter.
Step 2: Data Cleaning
- Remove Irrelevant Information: Filter out any data that is not relevant to the domain or the tasks at hand.
- Handle Missing Data: Decide how to deal with missing values, whether to impute them or remove the affected records.
- De-duplicate Data: Eliminate duplicate records to prevent biased model training.
Step 3: Data Annotation
- Labeling: If necessary, label the data for supervised learning tasks. This may include tagging for sentiment, topic categories, or relevance.
- Validation: Have subject matter experts validate the annotations to ensure accuracy.
Step 4: Data Transformation
- Normalization: Standardize the text data to a common format, such as all lowercase, to reduce complexity.
- Tokenization: Convert text into tokens or words that the model can understand.
- Vectorization: Transform the tokens into numerical vectors using techniques such as TF-IDF or word embeddings.
Step 5: Data Chunking
- Segmentation: Break down large documents into smaller, more manageable chunks that can be easily processed by the system.
- Context Preservation: Ensure that chunks maintain enough context to be understandable and useful.
Step 6: Semantic Indexation
- Build Indexes: Use the vectorized form of your data to build semantic indexes that can be used for quick retrieval by the RAG system.
- Knowledge Graphs: Optionally, construct knowledge graphs to represent relationships and facts from the data, enhancing the retrieval quality.
Step 7: Data Augmentation
- Synthetic Data Generation: If needed, generate synthetic data to augment the dataset, particularly for edge cases or rare scenarios.
- Paraphrasing: Use paraphrasing tools to expand the dataset with variations of existing data points.
Step 8: Quality Assurance
- Data Review: Conduct a thorough review of the prepared data to ensure it meets the standards set for quality and relevance.
- Test Runs: Use a subset of the data to run preliminary tests on the system and evaluate the output.
Step 9: Dataset Splitting
- Training, Validation, and Test Sets: Split the data into distinct sets for training, validating, and testing the models.
- Balance Datasets: Ensure that the splits contain a balanced representation of the different classes or categories.
Step 10: Documentation
- Record Keeping: Document the data preparation process, including the sources, steps taken, and any issues encountered.
- Metadata: Create metadata for the dataset that describes its contents, structure, and any preprocessing steps applied.
Step 11: Storage and Management
- Secure Storage: Store the prepared data securely, with backups and encryption as necessary.
- Data Management System: Implement a data management system to organize, track, and retrieve datasets efficiently.
Step 12: Final Review and Approval
- Stakeholder Review: Have stakeholders review the prepared data and sign off before moving forward.
- Legal Compliance: Ensure that the data preparation process complies with all relevant data privacy laws and ethical standards.
System Architecture
Combining Infrastructure Architecture with Integration Architecture for your RagOps system involves not only planning the hardware and software resources but also how these components will interact and integrate to support the system’s operations efficiently. This combined approach ensures the system is scalable, reliable, secure, and cohesive in its functionality. Here’s a guide to defining this integrated architecture:
Infrastructure and Integration Architecture Guide
- Determine System Requirements
- Computational Needs: Assess the computational demands based on the complexity of the data and models.
- User Load: Estimate the expected number of users and queries to determine system load.
- Choose the Deployment Environment
- Deployment Options: Decide on cloud services, on-premises servers, or a hybrid solution.
- Provider Selection: Choose providers or hardware based on performance, cost, and compliance.
- Plan for Scalability and Integration
- Scalable Architecture: Ensure the system can handle increased data volume and user traffic.
- Integrated Scalability: Plan for how different components will scale together, maintaining system integrity and performance.
- Design Data Storage and Integration Solutions
- Database Selection: Select appropriate database types (SQL, NoSQL, etc.) for your data.
- Data Redundancy and Recovery: Implement backup solutions and disaster recovery plans.
- Data Integration: Plan how data will flow between these storage solutions and other system components.
- Define Network and Integration Architecture
- Network Topology: Outline the network setup, including security measures like firewalls.
- Integration Points: Identify and plan for secure integration points for users and other systems.
- Processing Units and Distributed Computing
- Hardware Selection: Decide between CPUs, GPUs, or TPUs for your processing needs.
- Distributed Architecture: Plan for a distributed computing setup to enhance efficiency and reduce latency.
- Microservices, APIs, and System Integration
- Microservices Design: Break down the system into microservices for modularity.
- API Development: Develop APIs for internal communication and external access.
- Integration Flows: Map out how these microservices will integrate and communicate.
- Security Measures Across the Architecture
- Encryption and Access Controls: Implement robust security protocols.
- Compliance and Audits: Plan for regular audits to ensure ongoing compliance.
- Security Integration: Ensure security measures are integrated throughout the architecture.
- Monitoring, Logging, and Integration Health Checks
- System Monitoring: Set up monitoring for infrastructure health and performance.
- Logging System: Implement logging for troubleshooting and audits.
- Integration Monitoring: Monitor the health and performance of integration points.
- CI/CD Pipelines and Integration Testing
- CI/CD Setup: Establish CI/CD pipelines for smooth testing and deployment.
- Integration Testing: Include testing for how well different components integrate and function together.
- High Availability and Failover Strategies
- Redundancy Planning: Design the system for minimal downtime with failover strategies.
- Geographical Distribution: Consider redundant systems in different locations for high availability.
- Maintenance, Support, and Integration Updates
- Regular Maintenance: Schedule maintenance windows.
- Support Plans: Develop support plans for users and administrators.
- Update Strategies: Plan for updating integration points without disrupting the system.
- Documentation of the Combined Architecture
- Architecture Documentation: Create detailed documentation, including diagrams and specifications.
- Integration Documentation: Specifically document how different components will integrate and work together.
- Stakeholder Review and Feedback
- Present Architecture: Share the combined architecture with stakeholders for feedback.
- Incorporate Feedback: Adjust the architecture based on stakeholder inputs.
- Testing the Combined Architecture
- Load Testing: Conduct tests to validate the architecture’s design.
- Integration Testing: Perform specific tests to assess the efficiency and reliability of the integration architecture.
By thoughtfully combining the infrastructure and integration architecture, you ensure that your RagOps system is not only built on a solid foundation but also operates cohesively as an integrated whole. This approach facilitates system reliability, performance, and ease of maintenance, aligning with the overall goals and expected outcomes of the RagOps system.
Feedback
Developing a comprehensive Testing and Feedback section for your RagOps system is crucial to ensure its effectiveness, reliability, and user satisfaction. This section will directly link to the evaluation phase, providing essential data to refine and improve the system. Here’s a structured approach to creating this section:
Step 1: Define Testing Objectives
- Functionality Testing: Ensure the system functions as intended, responding accurately to queries.
- Performance Testing: Assess the system’s speed, responsiveness, and scalability.
- User Experience Testing: Evaluate the system’s usability and the satisfaction level of the end-users.
Step 2: Develop Test Plans
- Automated Testing: Implement automated test suites for continuous testing of the system’s functionalities and performance.
- Manual Testing: Plan manual testing scenarios, including edge cases and complex queries, to assess the system’s handling of real-world situations.
Step 3: User Feedback Collection
- Surveys and Questionnaires: Deploy surveys and questionnaires to gather user feedback on various aspects of the system.
- Interviews and Focus Groups: Conduct interviews and focus groups with a diverse group of users to gain deeper insights.
Step 4: Integration with Evaluation Framework
- Feedback Analysis: Analyze user feedback to identify common themes, issues, and areas for improvement.
- Metrics Alignment: Align feedback findings with the evaluation metrics to measure aspects like accuracy, relevancy, and user satisfaction.
Step 5: Usability Testing
- Test Scenarios: Create realistic user scenarios to test the system’s usability in various contexts.
- Heuristic Evaluation: Conduct heuristic evaluations to identify usability issues based on established usability principles.
Step 6: Stress and Load Testing
- Simulate High Load: Test the system under high load conditions to assess its performance and scalability.
- Identify Bottlenecks: Identify and address potential bottlenecks that could affect the system under stress.
Step 7: Security and Compliance Testing
- Security Audits: Conduct security audits to identify vulnerabilities and ensure data protection.
- Compliance Checks: Verify that the system complies with legal and regulatory standards, especially in data handling and privacy.
Step 8: Iterative Feedback Integration
- Continuous Improvement: Use the insights gained from testing and feedback to make iterative improvements to the system.
- Feature Updates: Update or add features based on user feedback and testing results.
Step 9: Documentation of Testing and Feedback
- Test Reports: Document the results of all testing activities, including automated and manual tests.
- Feedback Summary: Summarize user feedback and its implications for system improvement.
Step 10: Stakeholder Reporting
- Regular Updates: Provide regular updates to stakeholders on the findings from testing and feedback.
- Decision Making: Use testing and feedback results to inform decision-making processes regarding system updates and enhancements.
Step 11: Establish a Feedback Loop
- Ongoing Collection: Establish mechanisms for ongoing collection of user feedback.
- Responsive Adjustments: Ensure the system can quickly adapt to feedback, maintaining its relevance and effectiveness.
By implementing a robust Testing and Feedback section, you can continuously monitor and enhance the performance and user experience of your RagOps system. This process will also provide vital inputs to the evaluation phase, ensuring that the system evolves based on real-world usage and user insights.
RagOps, an innovative approach within the realm of Language Learning Models (LLMs), presents a groundbreaking solution in the field of AI-driven query answering and information retrieval. At its core, RagOps stands for Retrieval-Augmented Generation Operations, a system that seamlessly integrates the retrieval of relevant information with the generation of coherent and contextually accurate responses. The essence of RagOps lies in its unique ‘Infinity Loop’ concept, symbolizing a continuous cycle of improvement and adaptation.
The system encompasses various phases, each playing a vital role: starting from deep User Research to understand end-user needs, establishing robust Governance for ethical and legal compliance, selecting optimal AI Models for accuracy and efficiency, and meticulously preparing Data to fuel the system. It further progresses into designing versatile RAG Constructs tailored to specific requirements, implementing Guardrails for safety and relevance, and intricately planning Infrastructure & Integration for seamless operations. The cycle culminates in rigorous Evaluation and Feedback mechanisms, ensuring the system’s continual evolution and refinement.
RagOps stands out for its ability to adapt, its commitment to user-centric design, and its alignment with ethical standards. It’s not just an AI system; it’s a dynamic, evolving entity designed to meet the ever-changing demands of the digital world, making it a quintessential tool for businesses, researchers, and technologists seeking to harness the power of AI in understanding and responding to complex queries. With RagOps, the future of intelligent query answering is not just responsive; it’s proactive, adaptive, and endlessly innovative.